QR-код
QR-код[a] (англ. «код быстрого отклика»[2]; сокр. ) — тип матричных штриховых кодов (или двумерных штриховых кодов), изначально разработанных для автомобильной промышленности Японии. Его создателем считается Масахиро Хара[3]. Сам термин является зарегистрированным товарным знаком японской компании Denso. Штрихкод — считываемая машиной оптическая метка, содержащая информацию об объекте, к которому она привязана. QR-код использует четыре стандартизированных режима кодирования (числовой, буквенно-цифровой, двоичный и кандзи) для эффективного хранения данных; могут также использоваться расширения[4].






Система QR-кодов стала популярной за пределами автомобильной промышленности благодаря возможности быстрого считывания и большей ёмкости по сравнению со штрихкодами стандарта UPC. Расширения включают отслеживание продукции, идентификацию предметов, отслеживание времени, управление документами и общий маркетинг[5].
QR-код состоит из чёрных квадратов, расположенных в квадратной сетке на белом фоне, которые могут считываться с помощью устройств обработки изображений, таких как камера, и обрабатываться с использованием кодов Рида — Соломона до тех пор, пока изображение не будет надлежащим образом распознано. Затем необходимые данные извлекаются из шаблонов, которые присутствуют в горизонтальных и вертикальных компонентах изображения[5].
Описание
В те дни, когда не было QR-кода, компонентное сканирование проводилось на заводе-изготовителе Denso разными штрихкодами. Однако из-за того, что их было около 10, эффективность работы была крайне низкой, и работники жаловались, что они быстро устают, а также просили, чтобы был создан код, который может содержать больше информации, чем обычный штрихкод. Чтобы ответить на этот запрос работников, Denso-Wave была поставлена цель создать код, который может включать больше информации, чтобы позволить высокоскоростное компонентное сканирование.[6] Для этого Масахиро Хара, который работал в отделе разработки, начал разработку нового кода с 1992 года.[7] Вдохновением для создания QR-кода послужила игра го, в которую Масахиро Хара играл во время обеденного перерыва.[7] Он решил, что цель разработки состоит не только в увеличении объема кодовой информации, но и в «точном и быстром чтении», а также в том, чтобы сделать код читаемым и устойчивым к масляным пятнам, грязи и повреждениям, предполагая, что он будет использоваться на соответствующих производствах. QR-код был представлен японской компанией Denso-Wave, в 1994 году после двухлетнего периода разработки.[8][9][10] Он был разработан с учетом производственной системы компании «Toyota» канбан (точно в срок) для использования на заводах по производству автозапчастей и в распределительных центрах. Однако, поскольку он обладает высокой способностью обнаружения и исправления ошибок и сделан с открытым исходным кодом, он вышел из узкой сферы производственных цепочек поставок компании «Toyota» и начал использоваться в других сферах, что привело к тому, что теперь он широко используется не только в Японии, но и во всем мире. Огромная популярность штрихкодов в Японии привела к тому, что объём информации, закодированной в них, вскоре перестал устраивать промышленность. Японцы начали экспериментировать с новыми современными способами кодирования небольших объёмов информации в графической картинке. QR-код стал одним из наиболее часто используемых типов двумерного кода в мире.[11] Спецификация QR-кода не описывает формат данных.
В отличие от старого штрих-кода, который сканируют тонким лучом, QR-код определяется датчиком или камерой как двумерное изображение. Три квадрата в углах изображения и меньшие синхронизирующие квадратики по всему коду позволяют нормализовать размер изображения и его ориентацию, а также угол, под которым датчик расположен к поверхности изображения. Точки переводятся в двоичные числа с проверкой по контрольной сумме.
Основное достоинство QR-кода — это лёгкое распознавание сканирующим оборудованием, что даёт возможность использования в торговле, производстве, логистике.

Хотя обозначение «QR code» является зарегистрированным товарным знаком «DENSO Corporation», использование кодов не облагается никакими лицензионными отчислениями, а сами они описаны и опубликованы в качестве стандартов ISO.

Наиболее популярные программы просмотра QR-кодов поддерживают такие форматы данных: URL, закладка в браузер, Email (с темой письма), SMS на номер (c темой), MeCard, vCard, географические координаты, подключение к сети Wi-Fi.
Также некоторые программы могут распознавать файлы GIF, JPG, PNG или MID меньше 4 КБ и закодированный текст, но эти форматы не получили популярности.[13]
Применение
QR-коды больше всего распространены в Японии. Уже в начале 2000 года QR-коды получили столь широкое распространение в стране, что их можно было встретить на большом количестве плакатов, упаковок и товаров, там подобные коды наносятся практически на все товары, продающиеся в магазинах, их размещают в рекламных буклетах и справочниках. С помощью QR-кода даже организовывают различные конкурсы и ролевые игры. Ведущие японские операторы мобильной связи совместно выпускают под своим брендом мобильные телефоны со встроенной поддержкой распознавания QR-кода[14].
В настоящее время QR-код также широко распространён в странах Азии, постепенно развивается в Европе и Северной Америке. Наибольшее признание он получил среди пользователей мобильной связи — установив программу-распознаватель, абонент может моментально заносить в свой телефон текстовую информацию, подключаться к сети Wi-Fi, отправлять письма по электронной почте, добавлять контакты в адресную книгу, переходить по web-ссылкам, отправлять SMS-сообщения и т. д.
Как показало исследование, проведённое компанией comScore в 2011 году, 20 млн жителей США использовали мобильные телефоны для сканирования QR-кодов[15].
В Японии, Австрии и России QR-коды также используются на кладбищах и содержат информацию об усопшем[16][17][18].
В китайском городе Хэфэй пожилым людям были розданы значки с QR-кодами, благодаря которым прохожие могут помочь потерявшимся старикам вернуться домой[19].
QR-коды активно используются музеями[20], а также и в туризме, как вдоль туристических маршрутов, так и у различных объектов. Таблички, изготовленные из металла, более долговечны и устойчивы к вандализму.
Использование QR-кодов для подтверждения вакцинации
Одновременно с началом массовой вакцинации против COVID-19 весной 2021 года почти во всех странах мира началась выдача документов о вакцинации — цифровых или бумажных сертификатов, на которые повсеместно помещали QR-коды. К 9 ноября 2021 года QR-коды для подтверждения вакцинации или перенесённого заболевания (COVID-19) были введены в 77 субъектах Российской Федерации (в некоторых из них начало действия QR-кодов было отсрочено, чтобы дать населению возможность привиться). В Татарстане введение QR-кодов привело к столпотворениям на входах в метро и многочисленным конфликтам между пассажирами и кондукторами общественного транспорта[21].
Общая техническая информация
Самый маленький QR-код (версия 1) имеет размер 21×21 пиксель, самый большой (версия 40) — 177×177 пикселей. Связь номера версии с количеством модулей простая — QR-код последующей версии больше предыдущего строго на 4 модуля по горизонтали и по вертикали.
Существует четыре основные кодировки QR-кодов:
- Цифровая: 10 битов на три цифры, до 7089 цифр.
- Алфавитно-цифровая: поддерживаются 10 цифр, буквы от A до Z и несколько спецсимволов. 11 битов на два символа, до 4296 символов
- Байтовая: данные в любой подходящей кодировке (по умолчанию ISO 8859-1), до 2953 байт.
- Кандзи: 13 битов на иероглиф, до 1817 иероглифов.
Также существуют «псевдокодировки»: задание способа кодировки в данных, разбиение длинного сообщения на несколько кодов и т. д.
Для исправления ошибок применяется код Рида — Соломона с 8-битным кодовым словом. Есть четыре уровня избыточности: 7, 15, 25 и 30 %. Благодаря исправлению ошибок удаётся нанести на QR-код рисунок и всё равно оставить его читаемым.
Чтобы в коде не было элементов, способных запутать сканер, область данных складывается по модулю 2 со специальной маской. Корректно работающий кодер должен перепробовать все варианты масок, посчитать штрафные очки для каждой по особым правилам и выбрать самую удачную.
 1 – Введение
1 – Введение 2 – Структура
2 – Структура 3 – Кодирование
3 – Кодирование 4 – Уровни
4 – Уровни 5 – Протоколы
5 – Протоколы





Micro QR


Отдельно существует микро QR-код ёмкостью до 35 цифр.
Эффективность хранения данных по сравнению с традиционным QR кодом значительно улучшена благодаря использованию всего одной метки позиционирования, по сравнению с тремя метками в обычном QR коде. Из-за этого освобождается определённое пространство, которое может быть использовано под данные. Кроме того, QR код требует свободного поля вокруг кода шириной минимум в 4 модуля (минимальной единицы построения QR-кода), в то время как Micro QR код требует поля в два модуля шириной. Из-за большей эффективности хранения данных размер Micro QR кода увеличивается не столь значительно с увеличением объёма закодированных данных по сравнению с традиционным QR-кодом.
По аналогии с уровнями коррекции ошибок в QR-кодах Micro QR код бывает четырёх версий, М1-М4[22][23].
| Версия кода | Количество модулей | Уровень коррекции ошибок | Цифры | Цифры и буквы | Двоичные данные | Кандзи |
|---|---|---|---|---|---|---|
| M1 | 11 | - | 5 | - | - | - |
| M2 | 13 | L (7 %) | 10 | 6 | - | - |
| M (15 %) | 8 | 5 | - | - | ||
| M3 | 15 | L (7 %) | 23 | 14 | 9 | 6 |
| M (15 %) | 18 | 11 | 7 | 4 | ||
| M4 | 17 | L (7 %) | 35 | 21 | 15 | 9 |
| M (15 %) | 30 | 18 | 13 | 8 | ||
| Q (25 %) | 21 | 13 | 9 | 5 |
Кодирование данных
Закодировать информацию в QR-код можно несколькими способами, а выбор конкретного способа зависит от того, какие символы используются. Если используются только цифры от 0 до 9, то можно применить цифровое кодирование, если кроме цифр необходимо закодировать буквы латинского алфавита, пробел и символы $%*+-./:, используется алфавитно-цифровое кодирование. Ещё существует кодирование кандзи, которое применяется для кодирования китайских и японских иероглифов, и побайтовое кодирование. Перед каждым способом кодирования создаётся пустая последовательность бит, которая затем заполняется.
Цифровое кодирование
Этот тип кодирования требует 10 бит на 3 символа. Вся последовательность символов разбивается на группы по 3 цифры, и каждая группа (трёхзначное число) переводится в 10-битное двоичное число и добавляется к последовательности бит. Если общее количество символов не кратно 3, то если в конце остаётся 2 символа, полученное двузначное число кодируется 7 битами, а если 1 символ, то 4 битами.
Например, есть строка «12345678», которую надо закодировать. Последовательность разбивается на числа: 123, 456 и 78, затем каждое число переводится в двоичный вид: 0001111011, 0111001000 и 1001110, и объединяется это в один битовый поток: 000111101101110010001001110.
Буквенно-цифровое кодирование
В отличие от цифрового кодирования, для кодирования 2 символов требуется 11 бит информации. Последовательность символов разбивается на группы по 2, в группе каждый символ кодируется согласно таблице «Значения символов в буквенно-цифровом кодировании». Значение первого символа умножается на 45, затем к этому произведению прибавляется значение второго символа. Полученное число переводится в 11-битное двоичное число и добавляется к последовательности бит. Если в последней группе остаётся один символ, то его значение кодируется 6-битным числом.Рассмотрим на примере: «PROOF». Разбиваем последовательность символов на группы: PR, OO, F. Находим соответствующие значения символам к каждой группе (смотрим в таблицу): PR — (25,27), OO — (24,24), F — (15). Находим значения для каждой группы: 25 × 45 + 27 = 1152, 24 × 45 + 24 = 1104, 15 = 15. Переводим каждое значение в двоичный вид: 1152 = 10010000000, 1104 = 10001010000, 15 = 001111. Объединяем в одну последовательность: 1001000000010001010000001111.
Байтовое кодирование
Таким способом кодирования можно закодировать любые символы. Входной поток символов кодируется в любой кодировке (рекомендовано в UTF-8), затем переводится в двоичный вид, после чего объединяется в один битовый поток.
Например, слово «Мир» кодируем в Unicode (HEX) в UTF-8:М — D09C; и — D0B8; р — D180. Переводим каждое значение в двоичную систему счисления: D0 = 11010000, 9C = 10011100, D0 = 11010000, B8 = 10111000, D1 = 11010001 и 80 = 10000000; объединяем в один поток битов: 11010000 10011100 11010000 10111000 11010001 10000000.
Кандзи
В основе кодирования иероглифов (как и прочих символов) лежит визуально воспринимаемая таблица или список изображений иероглифов с их кодами. Такая таблица называется «character set». Для японского языка основное значение имеют две таблицы символов: JIS 0208:1997 и JIS 0212:1990. Вторая из них служит в качестве дополнения по отношению к первой. JIS 0208:1997 разбита на 94 страницы по 94 символа. К примеру, страница 4 — хирагана, 5 — катакана, 7 — кириллица, 16—43 — кандзи уровня 1, 48—83 — кандзи уровня 2. Кандзи уровня 1 («JIS дайити суйдзюн кандзи») упорядочены по онам. Кандзи уровня 2 («JIS дайни суйдзюн кандзи») упорядочены по ключам, и внутри них — по количеству черт.
Добавление служебной информации
После определения версии кода и кодировки необходимо определиться с уровнем коррекции ошибок. В таблице представлены максимальные значения уровней коррекции для различных версий QR-кода. Для исправления ошибок применяется код Рида — Соломона с 8-битным кодовым словом.
Таблица. Максимальное количество информации.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 152 | 272 | 440 | 640 | 864 | 1088 | 1248 | 1552 | 1856 | 2192 | 2592 | 2960 | 3424 | 3688 | 4184 | 4712 | 5176 | 5768 | 6360 | 6888 |
| M | 128 | 224 | 352 | 512 | 688 | 864 | 992 | 1232 | 1456 | 1728 | 2032 | 2320 | 2672 | 2920 | 3320 | 3624 | 4056 | 4504 | 5016 | 5352 |
| Q | 104 | 176 | 272 | 384 | 496 | 608 | 704 | 880 | 1056 | 1232 | 1440 | 1648 | 1952 | 2088 | 2360 | 2600 | 2936 | 3176 | 3560 | 3880 |
| H | 72 | 128 | 208 | 288 | 368 | 480 | 528 | 688 | 800 | 976 | 1120 | 1264 | 1440 | 1576 | 1784 | 2024 | 2264 | 2504 | 2728 | 3080 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7456 | 8048 | 8752 | 9392 | 10208 | 10960 | 11744 | 12248 | 13048 | 13880 | 14744 | 15640 | 16568 | 17528 | 18448 | 19472 | 20528 | 21616 | 22496 | 23648 |
| M | 5712 | 6256 | 6880 | 7312 | 8000 | 8496 | 9024 | 9544 | 10136 | 10984 | 11640 | 12328 | 13048 | 13800 | 14496 | 15312 | 15936 | 16816 | 17728 | 18672 |
| Q | 4096 | 4544 | 4912 | 5312 | 5744 | 6032 | 6464 | 6968 | 7288 | 7880 | 8264 | 8920 | 9368 | 9848 | 10288 | 10832 | 11408 | 12016 | 12656 | 13328 |
| H | 3248 | 3536 | 3712 | 4112 | 4304 | 4768 | 5024 | 5288 | 5608 | 5960 | 6344 | 6760 | 7208 | 7688 | 7888 | 8432 | 8768 | 9136 | 9776 | 10208 |
После определения уровня коррекции ошибок необходимо добавить служебные поля, они записываются перед последовательностью бит, полученной после этапа кодирования. В них указывается способ кодирования и количество данных. Значение поля способа кодирования состоит из 4 бит, оно не изменяется, а служит знаком, который показывает, какой способ кодирования используется. Оно имеет следующие значения:
- 0001 для цифрового кодирования,
- 0010 для буквенно-цифрового и
- 0100 для побайтового
Пример:
Ранее в примере байтового кодирования кодировалось слово «Мир», при этом получилась следующая последовательность двоичного кода:
11010000 10011100 11010000 10111000 11010001 10000000, содержащая 48 бит информации.
Пусть необходим уровень коррекции ошибок Н, позволяющий восстанавливать 30 % утраченной информации. По таблице максимальное количество информации выбирается оптимальная версия QR-кода (в данном случае 1 версия, которая позволяет закодировать 72 бита полезной информации при уровне коррекции ошибок Н).
Информация о способе кодирования: побайтовому кодированию соответствует поле 0100.
Указание количества данных (для цифрового и буквенно-цифрового кодирования — количество символов, для побайтового — количество байт): данная последовательность содержит 6 байт данных (в двоичной системе счисления: 110).
По таблице определяется необходимая длина двоичного числа — 8 бит. Дописываются недостающие нули: 00000110.
| Версия 1-9 | Версия 10-26 | Версия 27-40 | |
|---|---|---|---|
| Цифровое | 10 бит | 12 бит | 14 бит |
| Буквенно-цифровое | 9 бит | 11 бит | 13 бит |
| Побайтовое | 8 бит | 16 бит | 16 бит |
Вся информация записывается в порядке <способ кодирования> <количество данных> <данные>, получается последовательность бит:
0100 00000110 11010000 10011100 11010000 10111000 11010001 10000000.
Разделение на блоки
Последовательность байт разделяется на определённое для версии и уровня коррекции количество блоков, которое приведено в таблице «Количество блоков». Если количество блоков равно одному, то этот этап можно пропустить. А при повышении версии — добавляются специальные блоки.
Сначала определяется количество байт (данных) в каждом из блоков. Для этого надо разделить всё количество байт на количество блоков данных. Если это число не целое, то надо определить остаток от деления. Этот остаток определяет, сколько блоков из всех дополнены (такие блоки, количество байт в которых больше на один, чем в остальных). Вопреки ожиданию, дополненными блоками должны быть не первые блоки, а последние. Затем идёт последовательное заполнение блоков.
Пример: для версии 9 и уровня коррекции M количество данных — 182 байта, количество блоков — 5. Поделив количество байт данных на количество блоков, получаем 36 байт и 2 байта в остатке. Это значит, что блоки данных будут иметь следующие размеры: 36, 36, 36, 37, 37 (байт). Если бы остатка не было, то все 5 блоков имели бы размер по 36 байт.
Блок заполняется байтами из данных полностью. Когда текущий блок полностью заполняется, очередь переходит к следующему. Байтов данных должно хватить ровно на все блоки, не больше и не меньше.
Создание байтов коррекции
Процесс основан на алгоритме Рида — Соломона. Он должен быть применён к каждому блоку информации QR-кода. Сначала определяется количество байт коррекции, которые необходимо создать, а затем, с ориентиром на эти данные, создаётся многочлен генерации. Количество байтов коррекции на один блок определятся по выбранной версии кода и уровню коррекции ошибок (приведено в таблице).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7 | 10 | 15 | 20 | 26 | 18 | 20 | 24 | 30 | 18 | 20 | 24 | 26 | 30 | 22 | 24 | 28 | 30 | 28 | 28 | 28 | 28 | 30 | 30 | 26 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| M | 10 | 16 | 26 | 18 | 24 | 16 | 18 | 22 | 22 | 26 | 30 | 22 | 22 | 24 | 24 | 28 | 28 | 26 | 26 | 26 | 26 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 |
| Q | 13 | 22 | 18 | 26 | 18 | 24 | 18 | 22 | 20 | 24 | 28 | 26 | 24 | 20 | 30 | 24 | 28 | 28 | 26 | 30 | 28 | 30 | 30 | 30 | 30 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| H | 17 | 28 | 22 | 16 | 22 | 28 | 26 | 26 | 24 | 28 | 24 | 28 | 22 | 24 | 24 | 30 | 28 | 28 | 26 | 28 | 30 | 24 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
По количеству байтов коррекции определяется генерирующий многочлен (приведено в таблице).
| Количество байт коррекции | Генерирующий многочлен |
|---|---|
| 7 | 87, 229, 146, 149, 238, 102, 21 |
| 10 | 251, 67, 46, 61, 118, 70, 64, 94, 32, 45 |
| 13 | 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78 |
| 15 | 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105 |
| 16 | 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120 |
| 17 | 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136 |
| 18 | 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153 |
| 20 | 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190 |
| 22 | 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231 |
| 24 | 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21 |
| 26 | 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70 |
| 28 | 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123 |
| 30 | 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180 |
Расчёт производится исходя из значений исходного массива данных и значений генерирующего многочлена, причём для каждого шага цикла отдельно.
Объединение информационных блоков
На данном этапе имеется два готовых блока: исходных данных и блоков коррекции (из прошлого шага), их необходимо объединить в один поток байт. По очереди необходимо брать один байт информации из каждого блока данных, начиная от первого и заканчивая последним. Когда же очередь доходит до последнего блока, из него берётся байт и очередь переходит к первому блоку. Так продолжается до тех пор, пока в каждом блоке не закончатся байты. Есть исключения, когда текущий блок пропускается, если в нём нет байт (ситуация, когда обычные блоки уже пусты, а в дополненных ещё есть по одному байту). Так же поступается и с блоками байтов коррекции. Они берутся в том же порядке, что и соответствующие блоки данных.
В итоге получается следующая последовательность данных: <1-й байт 1-го блока данных><1-й байт 2-го блока данных>…<1-й байт n-го блока данных><2-й байт 1-го блока данных>…<(m — 1)-й байт 1-го блока данных>…<(m — 1)-й байт n-го блока данных><m-й байт k-го блока данных>…<m-й байт n-го блока данных><1-й байт 1-го блока байтов коррекции><1-й байт 2-го блока байтов коррекции>…<1-й байт n-го блока байтов коррекции><2-й байт 1-го блока байтов коррекции>…<l-й байт 1-го блока байтов коррекции>…<l-й байт n-го блока байтов коррекции>.
Здесь n — количество блоков данных, m — количество байтов на блок данных у обычных блоков, l — количество байтов коррекции, k — количество блоков данных минус количество дополненных блоков данных (тех, у которых на 1 байт больше).
Этап размещения информации на поле кода
На QR-коде есть обязательные поля, они не несут закодированной информации, а содержат информацию для декодирования. Это:
- Поисковые узоры
- Выравнивающие узоры
- Полосы синхронизации
- Код маски и уровня коррекции
- Код версии (с 7-й версии)
а также обязательный отступ вокруг кода. Отступ — это рамка из белых модулей, её ширина — 4 модуля.
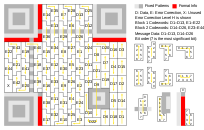
Поисковые узоры — это 3 квадрата по углам кроме правого нижнего. Используются для определения расположения кода. Они состоят из квадрата 3×3 из чёрных модулей, вокруг рамка из белых модулей шириной 1, потом ещё одна рамка из чёрных модулей, также шириной 1, и ограждение от остальной части кода — половина рамки из белых модулей шириной 1. Итого эти объекты имеют размер 8×8 модулей.
Выравнивающие узоры — появляются, начиная со второй версии, используются для дополнительной стабилизации кода, более точном его размещении при декодировании. Состоят они из 1 чёрного модуля, вокруг которого стоит рамка из белых модулей шириной 1, а потом ещё одна рамка из чёрных модулей, также шириной 1. Итоговый размер выравнивающего узора — 5×5. Стоят такие узоры на разных позициях в зависимости от номера версии. Выравнивающие узоры не могут накладываться на поисковые узоры. Ниже представлена таблица расположения центрального чёрного модуля, там указаны цифры — это возможные координаты, причём как по горизонтали, так и по вертикали. Эти модули стоят на пересечении таких координат. Отсчёт ведётся от верхнего левого узла, его координаты (0,0).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| - | 18 | 22 | 26 | 30 | 34 | 6, 22, 38 | 6, 24, 42 | 6, 26, 46 | 6, 28, 50 | 6, 30, 54 | 6, 32, 58 | 6, 34, 62 | 6, 26, 46, 66 | 6, 26, 48, 70 | 6, 26, 50, 74 | 6, 30, 54, 78 | 6, 30, 56, 82 | 6, 30, 58, 86 | 6, 34, 62, 90 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 |
| 6, 28, 50, 72, 94 | 6, 26, 50, 74, 98 | 6, 30, 54, 78, 102 | 6, 28, 54, 80, 106 | 6, 32, 58, 84, 110 | 6, 30, 58, 86, 114 | 6, 34, 62, 90, 118 | 6, 26, 50, 74, 98, 122 | 6, 30, 54, 78, 102, 126 | 6, 26, 52, 78, 104, 130 | 6, 30, 56, 82, 108, 134 | 6, 34, 60, 86, 112, 138 | 6, 30, 58, 86, 114, 142 | 6, 34, 62, 90, 118, 146 | 6, 30, 54, 78, 102, 126, 150 | 6, 24, 50, 76, 102, 128, 154 | 6, 28, 54, 80, 106, 132, 158 | 6, 32, 58, 84, 110, 136, 162 | 6, 26, 54, 82, 110, 138, 166 | 6, 30, 58, 86, 114, 142, 170 |
Полосы синхронизации — используются для определения размера модулей. Располагаются они уголком, начинается одна от левого нижнего поискового узора (от края чёрной рамки, но переступив через белую), идёт до левого верхнего, а оттуда начинается вторая, по тому же правилу, заканчивается она у правого верхнего. При наслоении на выравнивающий модуль он должен остаться без изменений. Выглядят полосы синхронизации как линии чередующихся между собой чёрных и белых модулей.
Код маски и уровня коррекции — расположен рядом с поисковыми узорами: под правым верхним (8 модулей) и справа от левого нижнего (7 модулей), и дублируются по бокам левого верхнего, с пробелом на 7 ячейке — там, где проходят полосы синхронизации, причём горизонтальный код в вертикальную часть, а вертикальный — в горизонтальную.
Код версии — нужен для определения версии кода. Находятся слева от верхнего правого и сверху от нижнего левого, причём дублируются. Дублируются они так — зеркальную копию верхнего кода поворачивают против часовой стрелки на 90 градусов. Ниже представлена таблица кодов, 1 — чёрный модуль, 0 — белый.
| Версия | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Код версии | 000010 011110 100110 | 010001 011100 111000 | 110111 011000 000100 | 101001 111110 000000 | 001111 111010 111100 | 001101 100100 011010 | 101011 100000 100110 | 110101 000110 100010 | 010011 000010 011110 | 011100 010001 011100 | 111010 010101 100000 | 100100 110011 100100 | 000010 110111 011000 | 000000 101001 111110 | 100110 101101 000010 | 111000 001011 000110 | 011110 001111 111010 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| 001101 001101 100100 | 101011 001001 011000 | 110101 101111 011100 | 010011 101011 100000 | 010001 110101 000110 | 110111 110001 111010 | 101001 010111 111110 | 001111 010011 000010 | 101000 011000 101101 | 001110 011100 010001 | 010000 111010 010101 | 110110 111110 101001 | 110100 100000 001111 | 010010 100100 110011 | 001100 000010 110111 | 101010 000110 001011 | 111001 000100 010101 |
Занесение данных
Оставшееся место делят на столбики шириной в 2 модуля и заносят туда информацию, причём делают это «змейкой». Сначала в правый нижний квадратик заносят первый бит информации, потом в его левого соседа, потом в тот, который был над первым и так далее. Заполнение столбцов ведётся снизу вверх, а потом сверху вниз и т. д., причём по краям заполнение битов ведётся от крайнего бита одного столбца до крайнего бита соседнего столбца, что задаёт «змейку» на столбцы с направлением вниз.Если информации окажется недостаточно, то поля просто оставляют пустыми (белые модули). При этом на каждый модуль накладывается маска.
 Описание полей QR-кода.
Описание полей QR-кода. Код маски и уровня коррекции, возможные XOR-маски
Код маски и уровня коррекции, возможные XOR-маски
 8-цветный код JAB, содержащий текст «Добро пожаловать в Википедию, бесплатную энциклопедию, которую может редактировать каждый».
8-цветный код JAB, содержащий текст «Добро пожаловать в Википедию, бесплатную энциклопедию, которую может редактировать каждый». Примеры цветного двухмерного кода большой емкости (HCC2D): (a) 4-цветный код HCC2D и (b) 8-цветный код HCC2D.
Примеры цветного двухмерного кода большой емкости (HCC2D): (a) 4-цветный код HCC2D и (b) 8-цветный код HCC2D. Версия 1
Версия 1 Функциональные области QR-кода версии 1
Функциональные области QR-кода версии 1 Версия 40
Версия 40 IQR-код
IQR-код










См. также
Примечания
Литература
- Бугаев Л. Мобильный маркетинг. Как зарядить свой бизнес в мобильном мире. — М.: Альпина Паблишер, 2012. — 214 с. — ISBN 978-5-9614-2222-1.
- ГОСТ Р ИСО/МЭК 18004-2015 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code
Ссылки
- Сайт компании Denso Wave, посвящённый QR-кодам (англ.)